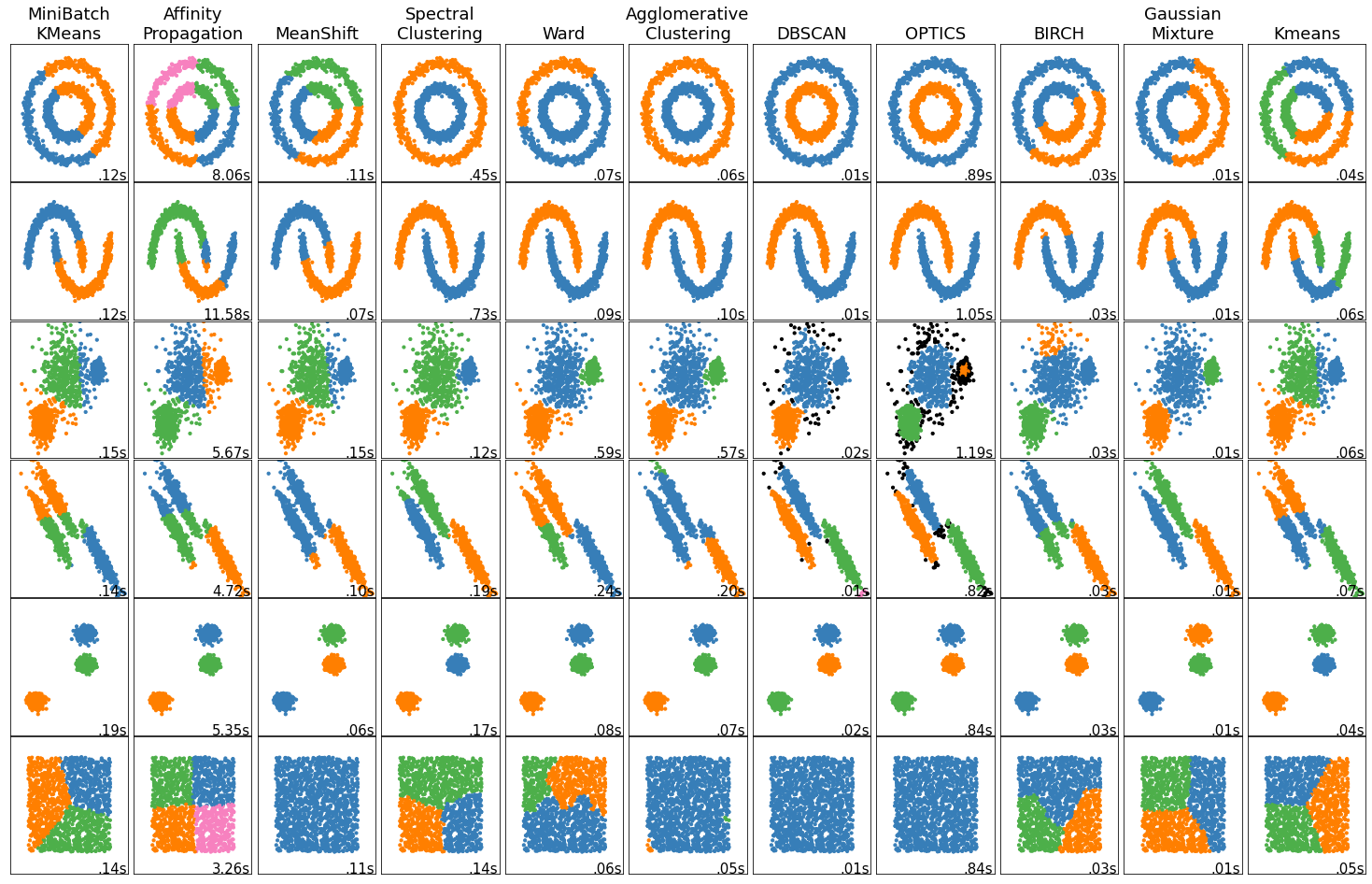
Clustering algorithms are unsupervised machine learning methods that group similar data points into separate 'clusters' based on their inherent similarity or patterns, without prior knowledge of labels. They're widely used for exploratory data analysis to understand data structure, identify patterns, and pre-process data before further modeling. In AI/ML, they find application in tasks such as anomaly detection, image segmentation, document categorization, and customer segmentation.
There are several different clustering algorithms to use, including:
Clustering performance is evaluated using metrics such as the Silhouette Coefficient (measuring intra-cluster cohesion and inter-cluster distance), Davies-Bouldin Index (compares within-cluster distances to nearest cluster distance), Dunn Index (comparative measure of compactness and separation), and Adjusted Rand Index (a comparison with known clusters) among others, depending on the problem at hand. These metrics reflect clustering quality, efficiency, and robustness to noise or outliers, allowing assessment of clustering algorithm performance.
Each approach has its unique strengths and weaknesses in tasks like anomaly detection, image segmentation, document categorization, customer segmentation, data cleaning, and finding unknown number of clusters.
Speaking from experience, they are all conditionally useful and worth exploring.